2021年09月16日
S3 同期の際に Lambda で自動的に CloudFront のキャッシュをパージする(Node.js 版)
先日の記事では、S3 同期の際に Lambda で自動的に CloudFront のキャッシュをパージする 仕組みをご紹介しましたが、その中で作成する Lambda 関数で、ランタイムに Python を選択していました。今回は Node.js を使って同じ仕組みを構築してみましょう。
全体の流れ
先日の記事 でご紹介している手順とほぼ同じで、「Lambda 関数の作成」のみが今回ご紹介する Node.js に変わります。
また今回、コードを差し替えるだけでは面白くないので、合わせて Node.js の動作に必要なモジュールを追加する手順もご紹介します。
準備
先日の記事 のうち、「前提」から「キャッシュパージの回数を記録するための S3 バケットを作成する」までを行ってください。
Lambda 関数の作成(Node.js 版)
新しい関数を作成します。関数名はここでは「limited-cloudfront-purge-by-file-nodejs」とし、ランタイムに「Node.js 14.x」を指定します。他の項目はデフォルトのまま [関数を作成] ボタンを押します。
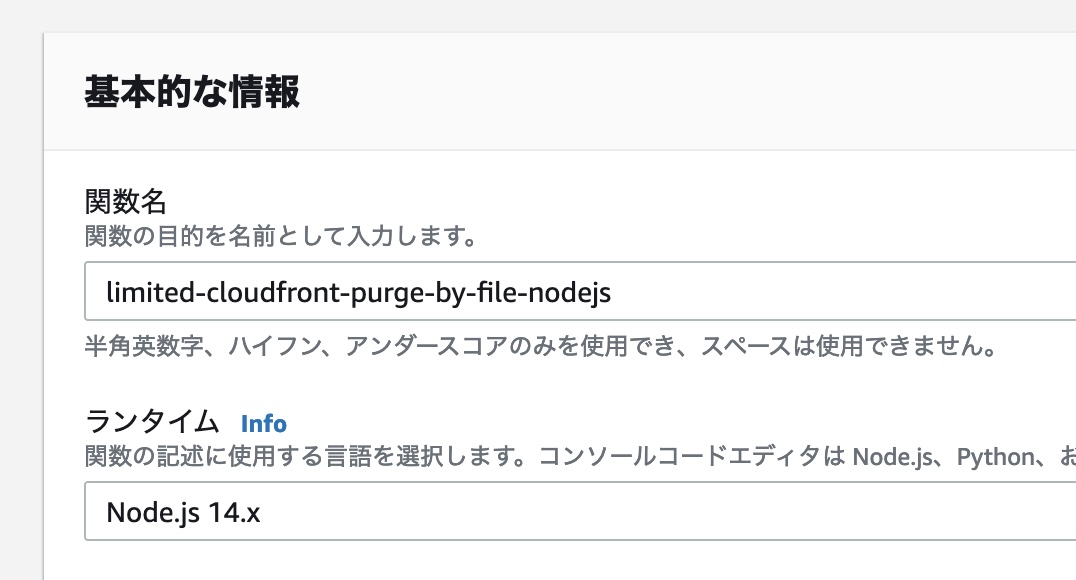
関数が作成されたら、コードソースに下記をコピー&ペーストします。DISTRIBUTION_ID, ORIGIN_BUCKET_NAME, COUNT_BUCKET_NAME をご利用環境に合わせて変更してください。また、ここでは、ファイル名が「.purge」のファイルに変更があったら、一日に 10 回までキャッシュのパージを行う設定になっています。状況に合わせて COUNT_MAX, TARGET_FILE を変更してください。
また、念のため、CloudWatch Logs に記録するための console.log を入れています。
require('date-utils');
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
const cloudfront = new AWS.CloudFront();
const DISTRIBUTION_ID = 'CloudFront の ID';
const ORIGIN_BUCKET_NAME = 'オリジンである S3 バケットの名前';
const COUNT_BUCKET_NAME='パージ回数を記録する S3 バケットの名前';
const COUNT_MAX=10;
const TARGET_FILE='.purge';
const pattern = new RegExp('^' + TARGET_FILE + '$');
exports.handler = async (event) => {
let dt = new Date();
let key = dt.toFormat("YYYY-MM-DD") + '.txt';
let count = 0;
await s3.getObject(
{
Bucket: COUNT_BUCKET_NAME,
Key: key,
}, (err, data) => {
if (! err) {
count = parseInt(data.Body.toString(),10);
if (isNaN(count)) {
count = 0;
}
}
}
).promise().catch(
function (error) {
count = 0;
}
);
console.log(count);
if ( count < COUNT_MAX ) {
console.log('NOT MAX');
for (let i = 0; i < event["Records"].length; i++) {
let item = event["Records"][i];
if (item["s3"]["bucket"]["name"] == ORIGIN_BUCKET_NAME ) {
if (item["s3"]["object"]["key"].match(pattern)) {
console.log('FILENAME PATTERN MATCHED');
let params = {
DistributionId: DISTRIBUTION_ID,
InvalidationBatch: {
Paths: {
Quantity: 1,
Items: ['/*']
},
CallerReference: dt.toFormat("YYYYMMDDHH24MISS")
}
};
await cloudfront.createInvalidation(params).promise();
console.log('INVALIDATION CREATED');
}
}
}
} else {
console.log('IS MAX');
return;
}
var params = {
Bucket: COUNT_BUCKET_NAME,
Key: key,
Body: String(count)
};
await s3.putObject(params).promise();
return;
};
パージ回数を記録するバケットには、「2021-08-06.txt」のように、日付ごとにファイルを作成し、内容としてパージ回数が記録していきます。月ごとにする場合は、"YYYY-MM-DD" の部分を "YYYY-MM" にしてください。合わせて COUNT_MAX も増やしたほうがいいかもしれません。
※ このコードでは日付が UTC となりますが、内容の簡略化のため、JST にする方法はここでは触れません
コードソースの編集が終わったら、[Deploy] ボタンを押してデプロイします。
このコード内では、日付の作成処理を簡易化するために date-utils を使用していますが、Lambda 標準では利用できません。続いてレイヤーの追加を行うことで date-utils を利用できるようにしていきます。
※ date-utils を使わずに動作させる場合は、dt.toFormat() 部分を任意のコードに置き換えてください
レイヤーの追加
ローカルで ZIP アーカイブを作成し、AWS にアップロードする流れになります。
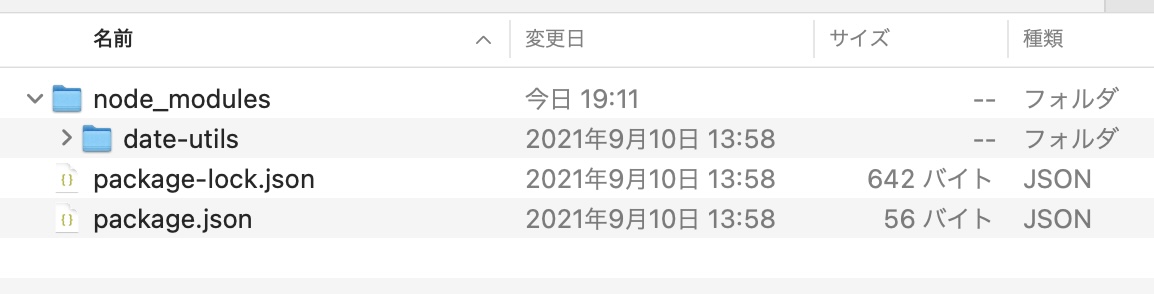
下記のように、新しく作成した nodejs フォルダの中で date-utils をインストールしたあと、nodejs フォルダを ZIP アーカイブし、「nodejs.zip」を作成します。
※ npm コマンドがインストールされていない場合はインストールを行ってください
mkdir nodejs
cd nodejs
npm install date-utils
cd ../
zip -r nodejs.zip nodejsインストールコマンド実行後の nodejs ディレクトリ内は下記のようになっています。
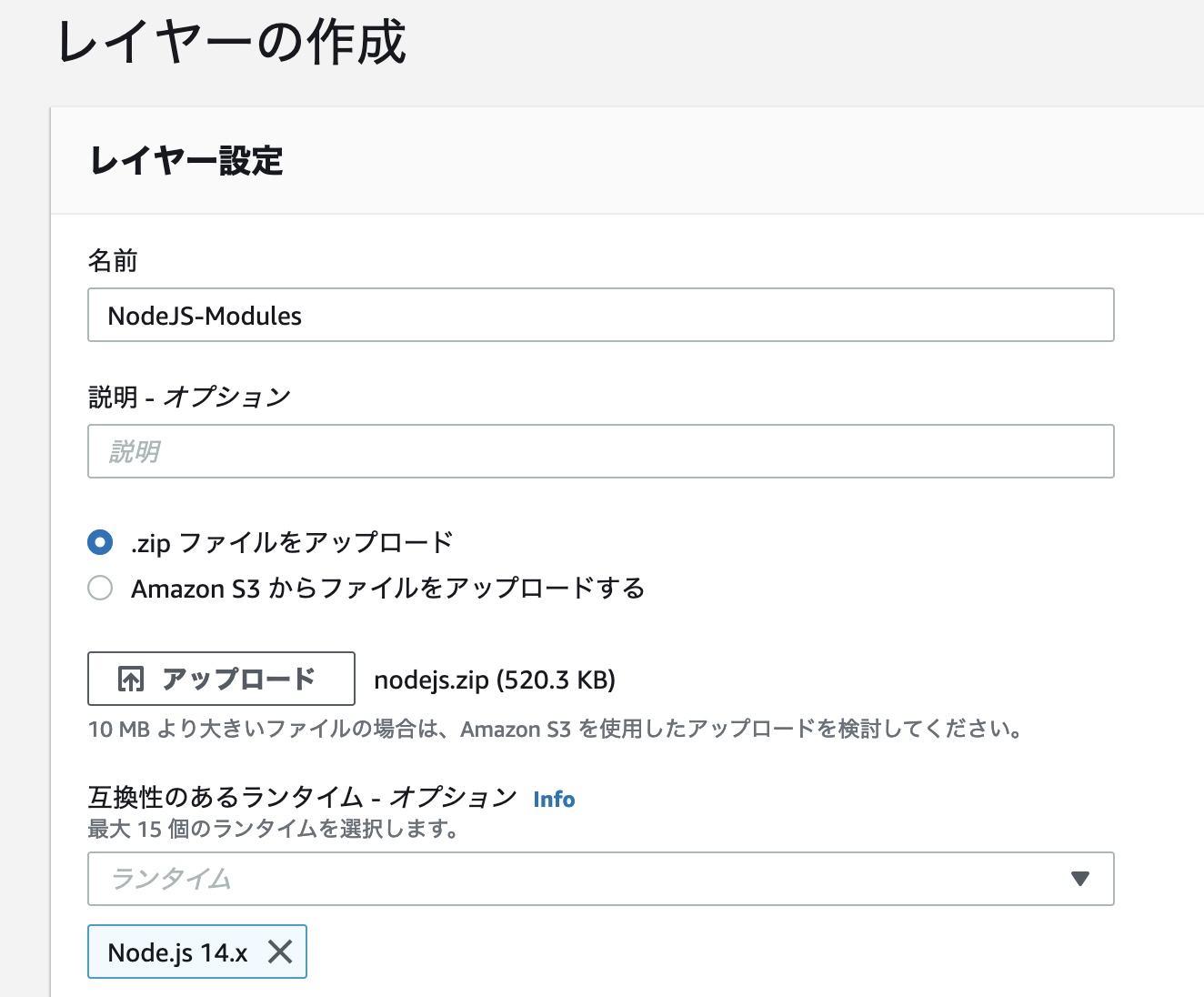
AWS コンソールに戻り、[Lambda] > 左メニュー [その他のリソース] 内 [レイヤー] > [レイヤーの作成] と進みます。ここでは、レイヤーの名前を「NodeJS-Modules」とし、[.zip ファイルをアップロード] から作成した「nodejs.zip」をアップロード、[互換性のあるランタイム] では「Node.js 14.x」を選択しました。
レイヤーの追加が終わったら、作成中の関数のコードソース編集画面に戻り、同ページ下部の [レイヤー] 内 [レイヤーの追加] を選択します。
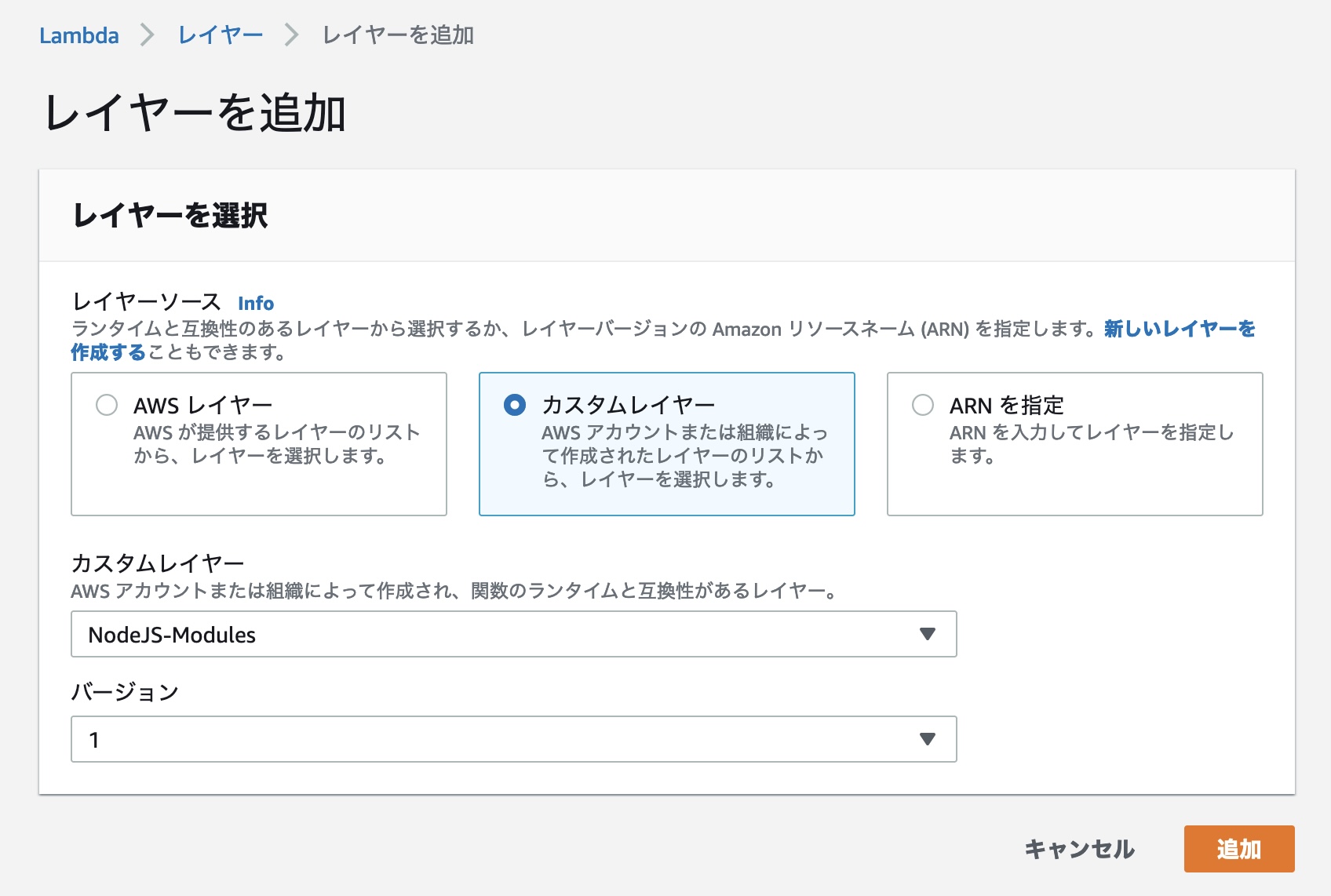
[レイヤーソース] では「カスタムレイヤー」を選択し、[カスタムレイヤー] で先ほど作成した「NodeJS-Modules」を、[バージョン] では「1」を選択し、[追加] ボタンを押します。
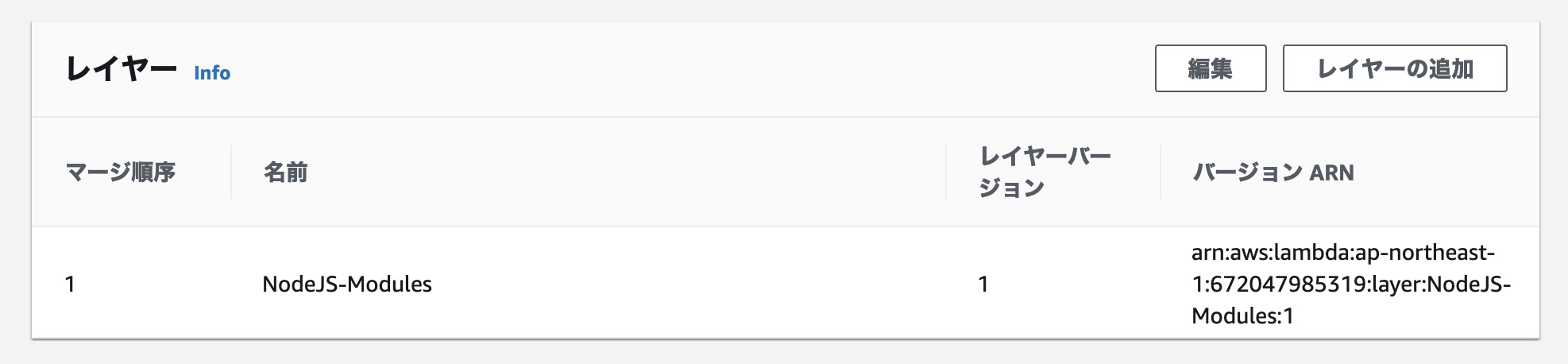
関数にレイヤーが追加されると、下記のような状態になります。これで date-utils が使えるようになりました。
アクセス権限の設定〜動作テスト
先日の記事 の「アクセス権限の設定」以降の手順を実施し、動作テストを行ってください。
なお、Lambda はデフォルトのタイムアウト設定が 3 秒ですが、CloudWatch Logs にタイムアウトが記録されるようであれば、タイムアウト設定を延ばしてみてください。この記事の作成時には 20 秒に設定していました。
お問い合わせ
環境構築やカスタマイズのご相談につきましては、お問い合わせフォームよりお問い合わせください。
- カテゴリー
- PowerCMS 5
- 技術情報



コメントを投稿する