※ この機能はエンタープライズ版以上のライセンスをご購入の場合のみご利用可能です
既存の HTML や XML 等のファイルから、記事/ウェブページへインポートすることができるため、サイトリニューアル等の際、過去のコンテンツ資産を有効に再利用できます。
また、指定したURLからコンテンツを取得してインポートを行うことができます。これにより、WordPress などの静的ファイルを持たない動的 CMS からの移行が容易になります。
情報を取り出すためのオプションとして、正規表現だけでなく、XPath やCSS パスを指定することができるので、ブラウザの開発者ツール等で対象を確認しながら設定できます。
Perl モジュール HTML::TreeBuilder::XPath、HTML::Selector::XPath が必要です。
インポートの設定
ファイルからのインポートの場合
事前準備
ワークスペース/スペースのサイト・パス以下の任意の場所に、取込み対象のファイル(HTML 等)をあらかじめ設置しておきます。HTML 内で利用されている画像等をあわせて設置しておくことでインポートと同時にアイテムとして登録することができます。
インポートの実行
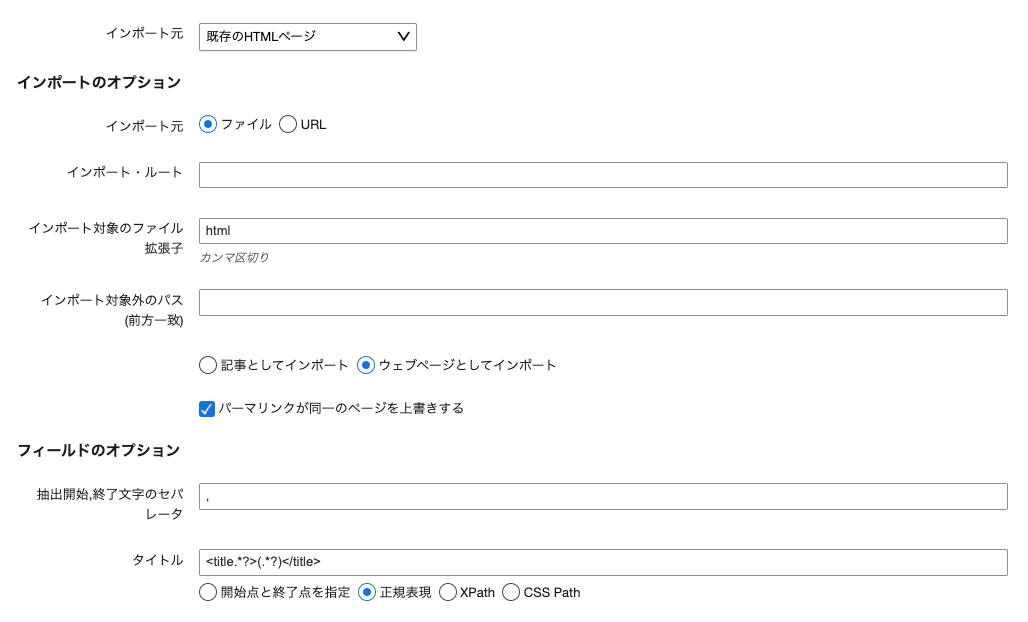
ワークスペース/スペースで [インポート/エクスポート] - [記事のインポート] を選択し、 [インポート元] で「既存の HTML ページ」を選択し、インポートオプションのインポート元「ファイル」を選択します。
| 設定項目 | 解説 | 初期値 | 設定例 |
|---|---|---|---|
| インポート元 |
「ファイル」もしくは「URL」からのインポートか選択してください。 |
「ファイル」にチェック | |
| インポート・ルート | インポート対象のファイルが設置しているルート・パスをサーバー上のフルパスで指定します。 | /var/www/html/import_root/ | |
| インポート対象のファイル拡張子(カンマ区切り) | インポート対象のファイルの拡張子を指定します。カンマ区切りで複数の種類のファイルを指定することもできます。 | html | html,php |
| インポート対象外のパス(前方一致) | インポート対象外のパスを指定します。カンマ区切りで複数指定も可能です。 | /var/www/html/import_root/cgi-bin | |
| ウェブページ(記事)としてインポート | ウェブページもしくは記事にインポートするか選択できます。 | ウェブページとしてインポートにチェック | |
| パーマリンクが同一のページを上書きする | インポート元ファイルの URL が既存のウェブページや記事のパーマリンクと同じ場合、それらの記事/ウェブページを上書きしてインポートします。このチェックを入れることで、インポートのリトライを繰り返すことが可能になります (併せて「フォルダ(カテゴリ)を作成する」を指定する必要があります)。ウェブページとして取り込む場合、ウェブページのアーカイブマッピングの設定を以下のように設定してください。 |
チェック |
URL を指定したインポートの場合
制限事項
会員サイトなどログインが必要なサイトのインポートは行えません。
インポートの実行
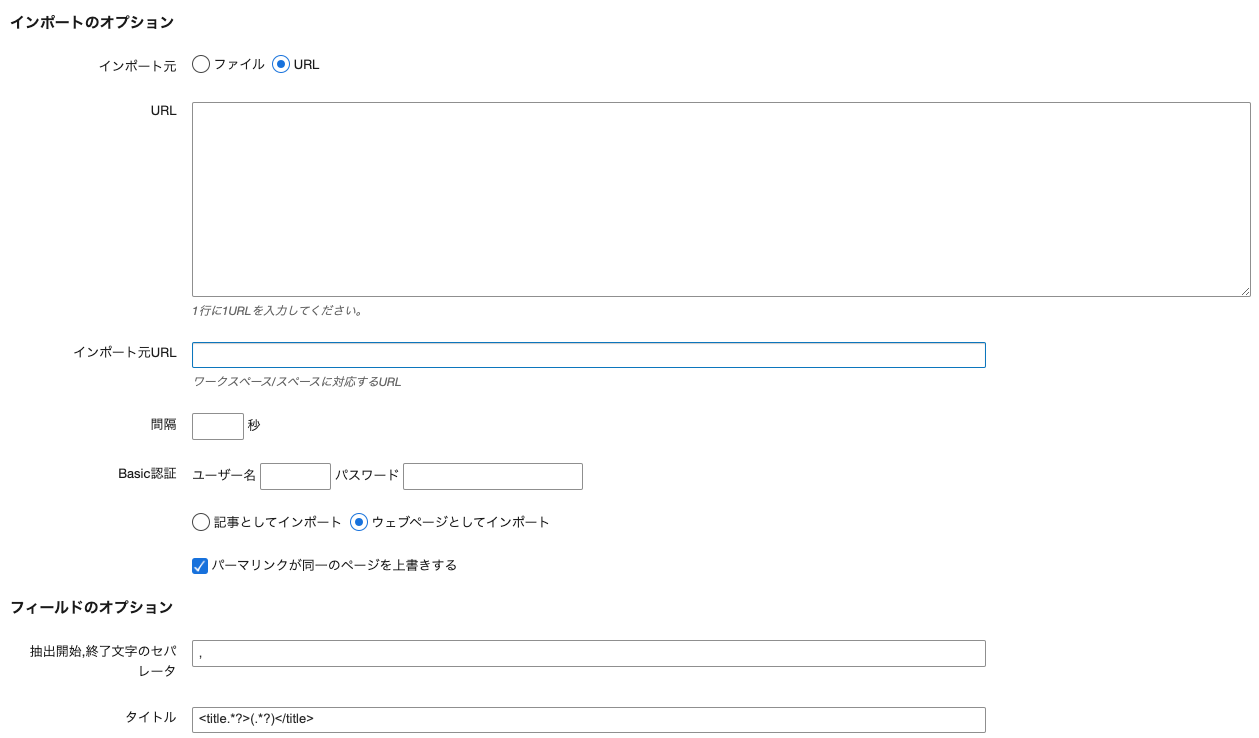
ワークスペース/スペースで [インポート/エクスポート] - [記事のインポート] を選択し、 インポート元「既存の HTML ページ」を選択し、インポートオプションのインポート元「URL」を選択します。
| 設定項目 | 解説 | 初期値 | 設定例 |
|---|---|---|---|
| インポート元 |
「ファイル」もしくは「URL」からのインポートか選択してください。 |
||
| URL | インポート対象 URL を設定します。1行に1 URL を入力してください。 | https://sample.com/index.html | |
| インポート元 URL | ワークスペース/スペースに対応する URL を設定してください。 | https://sample.com/ | |
| 間隔 | 複数 URL 指定した際、指定した URL をインポートする間隔を設定してください。 | 5 | |
| Basic認証 | インポートするURLに Basic 認証がかかっている場合、「ユーザ名」と「パスワード」を設定してください。 | ||
| ウェブページ(記事)としてインポート | ウェブページもしくは記事にインポートするか選択できます。 | ウェブページとしてインポートにチェック | |
| パーマリンクが同一のページを上書きする | インポート元ファイルの URL が既存のウェブページや記事のパーマリンクと同じ場合、それらの記事/ウェブページを上書きしてインポートします。このチェックを入れることで、インポートのリトライを繰り返すことが可能になります (併せて「フォルダ(カテゴリ)を作成する」を指定する必要があります)。ウェブページとして取り込む場合、ウェブページのアーカイブマッピングの設定を以下のように設定してください。 |
チェック |
フィールドのオプション
| 設定項目 | 解説 | 初期値 | 設定例 |
|---|---|---|---|
| 抽出開始,終了文字のセパレータ | 開始文字と終了文字を指定してフィールド値の抽出を行う場合に、開始文字と終了文字の区切り文字を指定します。例えば「,」(カンマ)を指定して、タイトルを <title>,</title> と指定した場合、HTMLのタイトル要素を記事/ウェブページのタイトルとしてインポートします。 |
, | # |
| タイトル | 記事/ウェブページのタイトルの抽出条件を指定します。 ・開始点と終了点を指定 「抽出開始,終了文字のセパレータ」として指定した区切り文字の前後のテキストの間の文字列を該当するフィールドにインポートします。 ・正規表現 正規表現で該当するフィールドにインポートします ・ XPath XPath で該当するフィールドにインポートします ・CSS Path CSS Path で該当するフィールドにインポートします |
<title.*?>(.*?)</title>; 正規表現にチェック |
・正規表現の場合 <div¥s>(.*?)</div> ・XPath の場合 //*[@title] ・CSS Pathの 場合 *[title] |
| 本文 | 記事/ウェブページの本文の抽出条件を指定します。 ・開始点と終了点を指定 「抽出開始,終了文字のセパレータ」として指定した区切り文字の前後のテキストの間の文字列を該当するフィールドにインポートします。 ・正規表現 正規表現で該当するフィールドにインポートします ・ XPath XPath で該当するフィールドにインポートします ・CSS Path CSS Path で該当するフィールドにインポートします |
<div\sclass=”asset-body”>(.*?)</div> 正規表現にチェック |
|
| 追記 | 記事/ウェブページの追記の抽出条件を指定します。 ・開始点と終了点を指定 「抽出開始,終了文字のセパレータ」として指定した区切り文字の前後のテキストの間の文字列を該当するフィールドにインポートします。 ・正規表現 正規表現で該当するフィールドにインポートします ・ XPath XPath で該当するフィールドにインポートします ・CSS Path CSS Path で該当するフィールドにインポートします |
正規表現にチェック | |
| 概要 | 記事/ウェブページの概要の抽出条件を指定します。 ・開始点と終了点を指定 「抽出開始,終了文字のセパレータ」として指定した区切り文字の前後のテキストの間の文字列を該当するフィールドにインポートします。 ・正規表現 正規表現で該当するフィールドにインポートします ・ XPath XPath で該当するフィールドにインポートします ・CSS Path CSS Path で該当するフィールドにインポートします |
<meta\s*?name=”description”\s*?content=”(.*?)”.*?> 正規表現にチェック |
|
| キーワード | 記事/ウェブページのキーワードの抽出条件を指定します。 ・開始点と終了点を指定 「抽出開始,終了文字のセパレータ」として指定した区切り文字の前後のテキストの間の文字列を該当するフィールドにインポートします。 ・正規表現 正規表現で該当するフィールドにインポートします ・ XPath XPath で該当するフィールドにインポートします ・CSS Path CSS Path で該当するフィールドにインポートします |
<meta\s*?name=”keywords”\s*?content=”(.*?)”.*?> 正規表現にチェック |
その他のオプション
| 設定項目 | 解説 | 初期値 |
|---|---|---|
| 設定を保存する | インポート設定を保存します。「パーマリンクが同一のページを上書きする」にあわせてチェックを入れることで、リトライを繰り返すことができます。 | チェック |
| フォルダ(カテゴリ)を作成する | インポート時にフォルダ(カテゴリ)を <mt:folderPath>/<mt:pagebasename>.html となるように自動生成します(ウェブページとして取り込む場合)。記事としてインポートする場合はカテゴリが階層化されて作成されます。 |
チェック |
| 記事/ウェブページをすべての親フォルダ(カテゴリ)に属するようにする | フォルダ(カテゴリ)を作成する際に、インポートによって作成された記事/ウェブページはすべてのフォルダ(カテゴリ)に属することになります。この場合、最下層のフォルダ(カテゴリ)がプライマリフォルダ(カテゴリ)になります。 ※「フォルダ(カテゴリ)を作成する」にチェックが必要です。 |
チェックなし |
| インポートした記事の所有者 | この設定の内容は反映されません。すべてインポートしたユーザーが所有者となります。 | 「自分の記事としてインポートする。」にチェック |
| インポートファイルをアップロード (オプション) | サーバー上のファイルのフルパスを、一行にひとつずつ記述されたファイルをアップロードすれば、リストのファイルのみを対象としたインポートを行います。 ※インポート元「URL」の場合、表示されません |
|
| テキストフォーマット | 記事/ウェブページのテキストフォーマットを設定します。 ※この項目は「設定を保存する」で保存されません。 |
対象のワークスペース/スペースのデフォルトのフォーマット |
| インポートするファイルの文字コード | 選択した文字コードでインポートを行います。 ※この項目は「設定を保存する」で保存されません。 |
Auto-detect |
| 記事の既定カテゴリ(オプション) | この設定の内容は反映されません。 | カテゴリを選択 |
| テスト実行 |
チェックを入れることで、インポートは行わず以下のフィールドに入る値を確認できます。
・タイトル
・本文(先頭200文字表示)
・追記(先頭200文字表示)
・概要
・カテゴリ/フォルダ
※登録されるアイテムの確認はできません |
チェック |
環境変数
| 環境変数 | 解説 | 初期値 |
|---|---|---|
| PowerImporterSSLVerifyNone | URLからのインポートにおいて SSL 証明書の検証を行わない場合に 1 を指定します。 環境変数 SSLVerifyNone が設定されている場合は PowerImporterSSLVerifyNone よりも SSLVerifyNone が優先して利用されます。 |
|
| PowerImporterSSLVersion | URLからのインポートでの通信において 許可する SSL のバージョンを指定します。 環境変数 SSLVersion が設定されている場合は PowerImporterSSLVersion よりも SSLVersion が優先して利用されます。 |
|
アイテムの同時取り込み
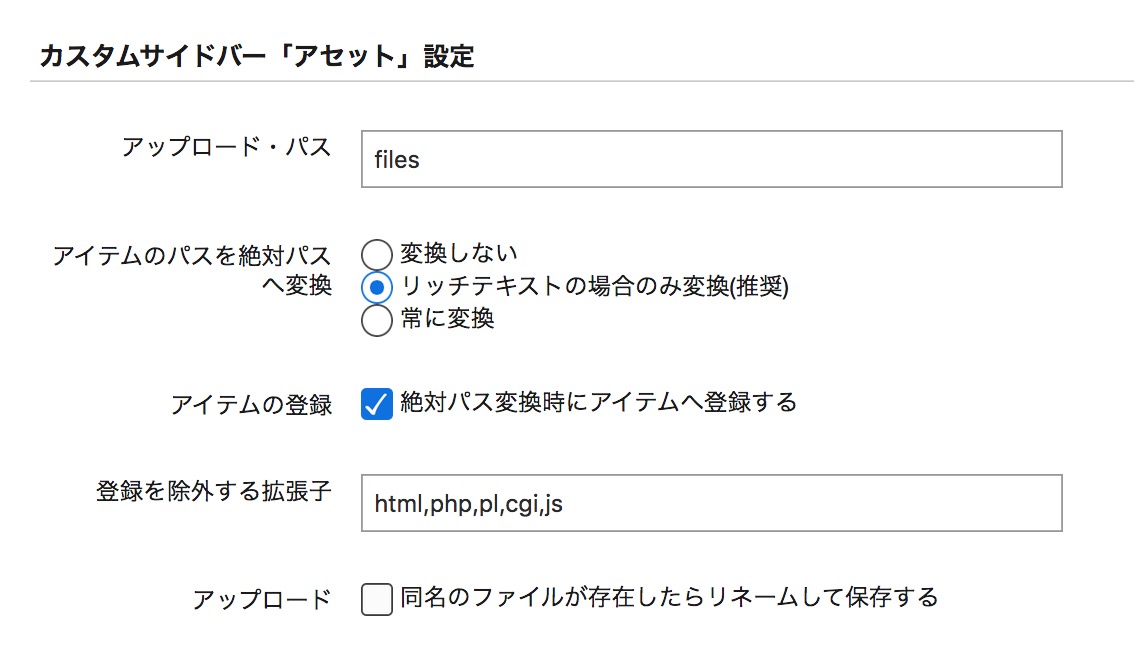
記事/ウェブページのインポートと同時にページに含まれる画像等を同時に「アイテム」として取り込むことができます。
インポートするワークスペース/スペースの PowerCMS 設定の「カスタムサイドバー「アセット」設定」で、「アイテムのパスを絶対パスに変換(常に変換)」「絶対パス変換時にアイテムへ登録する」の2つにチェックが入っている必要があります。
プラグインによる拡張
記事/ウェブページのインポート直後に発行されるコールバックに呼応して動作するプラグインを作成することで、カスタムフィールドへのデータ投入等を同時に行うことができます。
| コールバック | パラメータ | 解説 |
|---|---|---|
| cms_post_save.category cms_post_save.folder | $cb, $app, $obj, $original | インポート時にフォルダ、カテゴリが保存された直後に実行されます。このコールバックは、cms_post_save.page や cms_post_save.entry よりも前に実行されます。 |
| cms_post_save.page cms_post_save.entry | $cb, $app, $obj, $original | ウェブページ、記事が保存された直後に実行されます。 |
| cms_post_import.entry cms_post_import.page | $cb, $app, $entry, $path, $data | $entry にはインポート時に作成された記事/ウェブページ、$path にはインポート元のファイルのフルパス、$data にはインポートファイルのデータが丸ごと格納されて渡されます。このコールバックは、cms_post_save.page や cms_post_save.entry の直後に実行されます。 |
以下の例は HTML から本文を抽出する Perl モジュール HTML::ExtractContent を利用してウェブページの本文に抽出したテキストをインポートするサンプルです。
package MT::Plugin::ExtractContent;
use strict;
use MT;
use MT::Plugin;
use base qw( MT::Plugin );
our $plugin = __PACKAGE__->new({
name => 'ExtractContent',
});
MT->add_plugin( $plugin );
sub init_registry { my $plugin = shift;
$plugin->registry({
callbacks => {
'cms_post_import.page' => \&_cms_post_import,
},
});
}
sub _cms_post_import {
my ( $cb, $app, $entry, $path, $data ) = @_;
require HTML::ExtractContent;
my $extractor = HTML::ExtractContent->new;
$extractor->extract( $data );
my $text = $extractor->as_html;
$entry->text( $text );
$entry->save or die $entry->errstr;
}
1;- 一覧へ


